Kubernetes cronjob 101
In this article I will try to explain with some specific examples how to run Cronjob on Kubernetes.
Cronjob are basically Kubernetes jobs with a scheduling and some specific parameters to handle failure. Each Kubernetes job contains 1 to n pod.
Those pods runs a program defined for the task and are killed when the task is over.
The need
At JobTeaser we were migrating away from a machine learning recommendation service running on a (ec2 + Airflow + Flask) platform on which tasks were running each night, to Kubernetes. The reasoning behind this change was to improve the monitoring and scaling capacities of the whole system.
Since our new project didn’t require any complex workflow dependencies, someone suggested that, instead of our usual Airflow tasks where relationships between each operation are explicitly described by graphs, we should try using Kubernetes Cronjobs for extract load transform (ETL) batch scheduling.
Most teams would have said: “wait a minute, it’s totally insane to learn a new tech during a single cycle”, but we just said YOLO (Yahoo!!! an Opportunity to Learn the Obvious). So, here’s what we’ve discovered on the way.
Setup
So first you need to setup Kubernetes client kubectl following official documentation.
Then either you have a remote Kubernetes cluster setup already or you have a local minikube installed, both solutions work for this case.
Deploy a job on Kubernetes in 5 min
So… We’ll start with the most basic example we can use with the following cronjob configuration.
This cronjob will run one job every 5 minutes (using a cron format for scheduling) and display “Hello world”
To launch this job you just need to run the following command (‘create’ also works but don’t mix them together)
kubectl apply -f most_basic_cronjob.yaml
To check that the cronjob was created just use
kubectl get cronjob

So cronjob was named “test” based on the metadata.name value, the planning is the same as the one in spec.schedule. As a default function the job will run, so suspend value is False. There is currently no task running it (we didn’t plan it yet), Last Schedule and Age values are therefore void.
If we check the status of our scheduled jobs after 5 minutes, here’s what we’ll see.

We can see a job has been created and is currently running, Last schedule and Age are filled in. To check the job in detail we need to go down a notch.
kubectl get job

We can see here that a job was a created with a unique name and has not been completed yet, you can find the related pod by using the command.
kubectl describe job name_of_job
That will show the number of times the job has been restarted, full config of the job and the pod created. You can also use it on the cronjob itself.
kubectl describe cronjob test
Also if you want you can just run a job directly using the following (work with a kubectl version greater than 1.10.1)
kubectl create -f ./cronjob.yaml
Live editing of the cronjob
But even better than that, you can edit the cronjob on the fly by using the following command.
kubectl edit cronjob test
Wow! That’s a lot of information. Let’s remove some noise.
Even better, now you may want to understand the parameters available when you’re editing. Some are mandatory, others optional — here’s the breakdown.
Mandatory parameters with default values
concurrencyPolicy: This parameter is responsible for running your job in parallel with other jobs. The available values are either “Allow” or “Forbid”, but remember “Forbid” CANNOT GUARANTEE THAT ONLY ONE JOB WILL BE RUN AT ONCE.
failedJobHistoryLimit and successfulJobsHistoryLimit are just here to help trim the output of `kubectl get jobs` by deleting older entries.
suspend: If false, the cronjob is actively scheduling job, if true existing job will not be forced to terminate but new ones cannot be scheduled; this is useful for debugging when you want to stop your job from being launch or on the contrary set it to true by default and to launch it manually.
Optional parameters
activeDeadlineSeconds: Doesn’t kill or stop the job itself but deletes the pod on error (the job will be replaced by a new one at the scheduled time).
startingDeadlineSeconds: If for technical reasons (e.g. a cluster is down, …) a job cannot be started in the interval between schedule time and startingDeadlineSeconds it will not start at all. This is useful for long jobs when you should wait for the next one or short jobs with high frequency that can stack up if they aren’t stopped.
backoffLimit: Number of retries for pods launched by the job. If you want your pods to never restart, you need to set it at 0. However due to some issue where pod can’t be restarted beyond backoffLimit it’s better, if you use “restartPolicy : Never”.
Here is a more detailed cronjob example with most of the parameters:
What we have here is a job that will run a script called job_offers.py that is expected to run for 45 minutes each day at 16h30, 17h30, 18h30 and 19h30 UTC.
We don’t want multiple runs to be launched so we use currencyPolicy : “Forbid”. We don’t want it to runs for more than the expected time and overlap with the next execution time slot either, so we use startDeadlineSeconds: 600. This way a new job can only start when it has enough time to complete, like this:
16h30–16h40, 17h30-17h40, 18h30–18h40, and 19h30-19h40.
To complicate the exercise you can sometimes have jobs that will hang on a resource and go beyond 45min. In this case we want to kill this job and expect the next one to be completed. To do so, we specify an activeDeadlineSeconds: 3300 of 55minutes so the job will necessarily be killed before the next one.
We also want to keep better track of failure so we increase failedJobsHistoryLimit up to 10.
Nota Bene
One of the most confusing concepts of Cronjobs is that jobs can never fail. How come? There are 3 options of what can happen to them:
- Waiting for completion
- Completed
- Deleted
If the pod that executes the job fails for any reason (Out of memory, code failure, etc) each job will clutter the listing of jobs waiting for completion but won’t prevent the next job from running because they don’t have an active pod. That’s why it’s important to remember to also check that the pods are still running when managing cronjob and if not to delete jobs that can no longer complete.
kubectl delete job job_id
Also, activeDeadlineSeconds will not kill the job on the spot. It will start by deleting the pod and you will have a trace of this event in the job info acquired by the command kubectl describe job job_id, but after a new job is scheduled this job will be deleted for good.

So far I would say that cronjobs aren’t a suitable solution that work for lot of data workflows mainly because you can’t have strong guarantees between jobs. However, it could be a good idea to use them if your jobs match the following criteria:
- Can be run concurrently (no lock on database)
- Have predictable memory usage (In case you use Limit on the pod)
- Job can handle dependent job failure
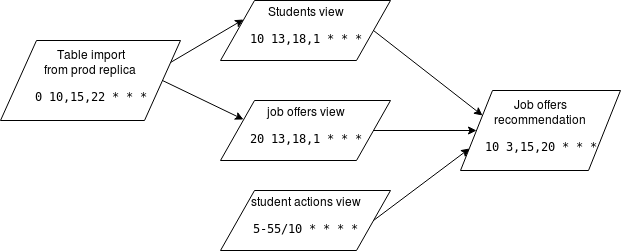
To give you an example, here what we have currently:
- One job that imports data in one shot
- 3 incremental views, the incremental part is important because that help us to handle import failures for both job that rely on it.
- A job doing the machine learning based recommendation, we only keep the last valid run.
- All jobs run at least 3 time a day to catch potential failures early on and act quickly.
Also it’s critical that you don’t rely too much on kubernetes commands to monitor your cronjob, at JobTeaser we use Datadog and ELK.
In the first part we focused on how to set up your first cronjob with the proper configuration and manipulate them with the Kubernetes cli. In this second part, we will give you a more detailed explanation of our workflow to launch and monitor our cronjob in production at
One issue we faced with our initial workflow was that not all of our jobs could be run concurrently, so when we were working on separate branches, we would create a lock on stateful resource such as a database.
The solution we came up with, relies on using the –from option when creating a job that expects a deployed cronjob
So when we start working on a new cronjob, our workflow is as follows:
- Create a suspended cronjob
- Check cronjob deployment
- Create a job from this cronjob with –from and check out the result
- Goto 1 until it work as expected
- Deploy it in production

This help avoids the issue of manually changing schedules after each deployment to start the jobs, or letting bugged job stack up, possibly locking down resources.
The limitation when creating job this way is that you can’t alter it.
Therefore, what will you do if you have to handle occasional operations such as catching up for ETL job or rerun failed job with increased limits (timeout, CPU, …) ?
For example, let’s say you have a cronjob that runs every day and uses “yesterday” as starting date by default. What we do is rely on command line parameters for the script and let it set a default value for which there is no input. This way we can manually edit the cronjob:
Now that you have this code in production if you want to rerun it using previous dates, what you can do is create a duplicate of the cronjob.
Edit its content to reflect your new limitations (CPU, RAM, deadline) and then create a job from your duplicated cronjob (I recommend setting “suspend” to initially true to avoid concurrent runs 😉 ) without impacting the one handling the normal run.
As we said, you need to rely on a script to handle the setup of a default value because you can’t call Linux command in you args, like date for example.
But did you know that you can use variable sets in env and envFrom in your script? You just need to call them using $() instead of ${}. It can be useful if you don’t want your script to rely on env variables
It’s really convenient to be able to raise an alert when a job fails, sadly as we saw in the previous article this is not always easy due to the job itself, so what we do now is to generate a log at the start and the end on the pod runtime using the lifecycle option in our cronjob definition
But keep in mind that if you use a docker container with an entrypoint you can run into some issue where the lifecycle will be executed AFTER the entrypoint.
Another great feature of Kubernetes is the init containers option, it consists of a list of ordered containers that will be run sequentially.
Each container waiting for the previous one to finish before launching, this is mainly used with the service API to sync them when deploying.
But this also works with a cronjob, so we can use them to do some sync or clean up before starting a job.
So, in conclusion, even if the cronjob API itself didn’t evolve much since part 1, there are many ways to improve your current use by looking at other tools in Kubernetes whether it is kubectl, the API options or even by integrating it to your own CI.
Credits: https://medium.com/@cols-knil