SQL vs. NoSQL Database: When to Use, How to Choose
How do you choose a database? Maybe, you assess whether the use case needs a Relational database. Depending on the answer, you pick your favorite SQL or NoSQL datastore, and make it work. It is a prudent tactic: a known devil is better than an unknown angel.
Picking the right datastore can simplify your application. A wrong choice can add friction. This article will help you expand your list of known devils with an in-depth overview of various datastores. It covers the following:
- Database parts that define a datastore’s characteristics.
- Datastores categorized by data types: deep dive into databases for unstructured, structured (SQL/tabular), and semi-structured (NoSQL) data.
- When to use NoSQL vs. SQL database.
- Differences between SQL and NoSQL databases.
- Datastores specialized for various NoSQL use cases.
- Decision Tree Cheatsheet to navigate the landscape of on-prem and on-cloud datastore choices.
Inside a Database
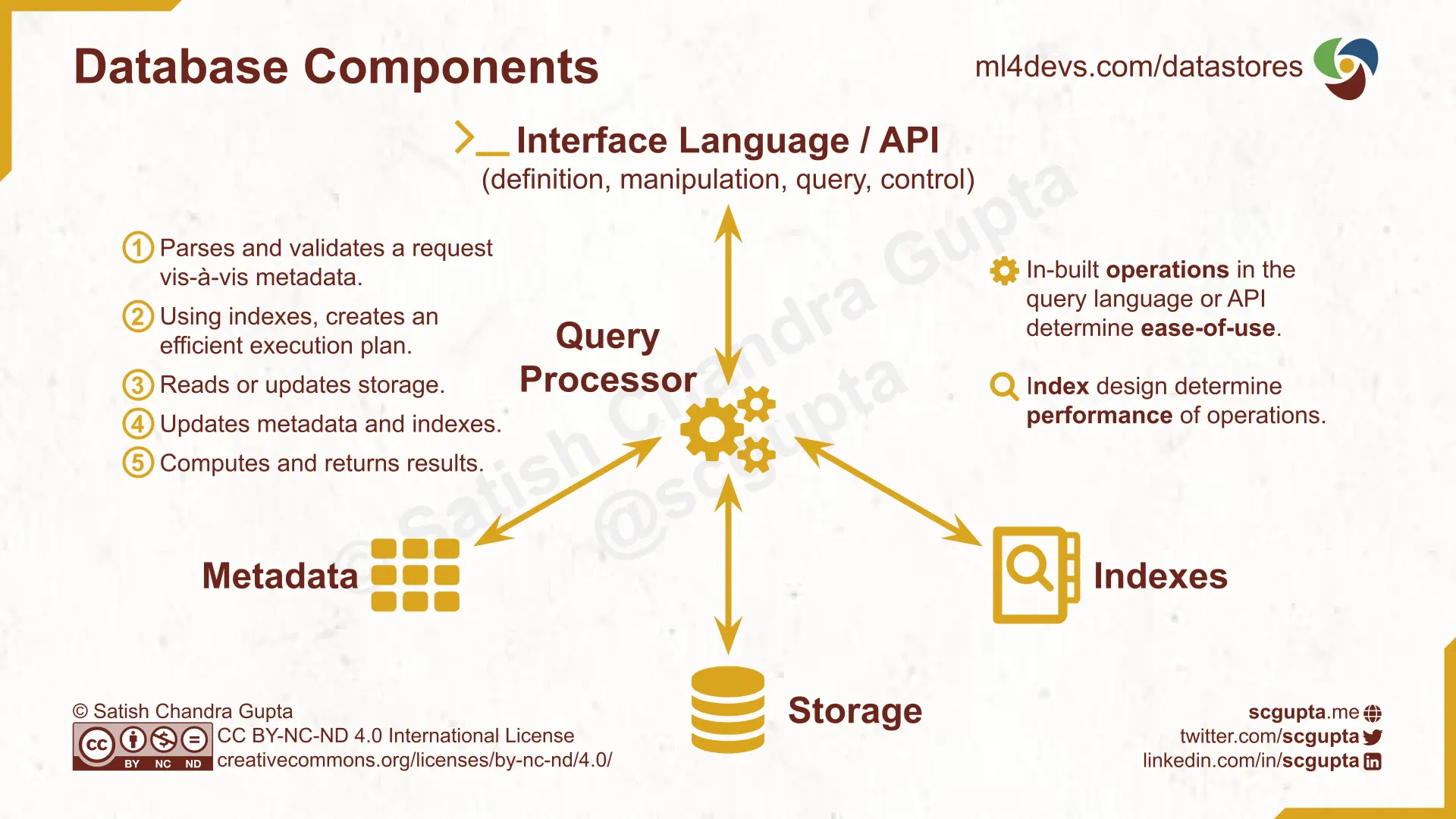
A high-level understanding of how databases work helps in evaluating alternatives. Databases have 5 components: interface, query processor, metadata, indexes, and storage:
- Interface Language or API: Each database defines a language or API to interact with it. It covers definition, manipulation, query, and control of data and transactions.
- Query Processor: The “CPU” of the database. Its job is to process incoming requests, perform needed actions, and return results.
- Storage: The disk or memory where the data is stored.
- Indexes: Data structures to quickly locate the queried data in the storage.
- Metadata: Meta-information of data, storage. and indexes (e.g., catalog, schema, size).
The Query Processor performs the following steps for each incoming request:
- Parses the request and validates it against the metadata.
- Creates an efficient execution plan that exploits the indexes.
- Reads or updates the storage.
- Updates metadata and indexes.
- Computes and returns results.
To determine a datastore matches your application needs, you need carefully examine:
- Operations supported by the interface. If the computations you require are in-built, you will need to write less code.
- Available indexes. It will determine how fast your queries run.
In the next sections, let’s examine operations and indexes in datastores for various data types.
When to Use Blob Storage
The file system is the simplest and oldest datastore. We use it every day to store all kinds of data. Blob Storage is a hyper-scale distributed version of the filesystem. It is used to store unstructured data.
Blob’s backronym is Binary Large OBjects. You can store any kind of data. Therefore blob datastore has no role in interpreting the data:
- Blob supports CRUD (create, read, update, delete) operations at the file level.
- The directory or file path is the index.
So you can quickly locate and read the file. But locating something within a file requires a sequential scan. Documents, images, audio, and video files are stored in blobs.
When to Use SQL Database
SQL databases are suitable for storing structured data. Data is stored in a table. Each record (row) has the same number of attributes (columns) of the same type.
There are two kinds of applications:
- Online Transaction Processing (OLTP): Capture, store, and process data from transactions in real-time.
- Online Analytical Processing (OLAP): analyze aggregated historical data from OLTP applications.
OLTP applications need datastores that support low latency reads and writes of individual records. OLAP applications need datastores that support high throughput reads on a large number of (read-only) records.
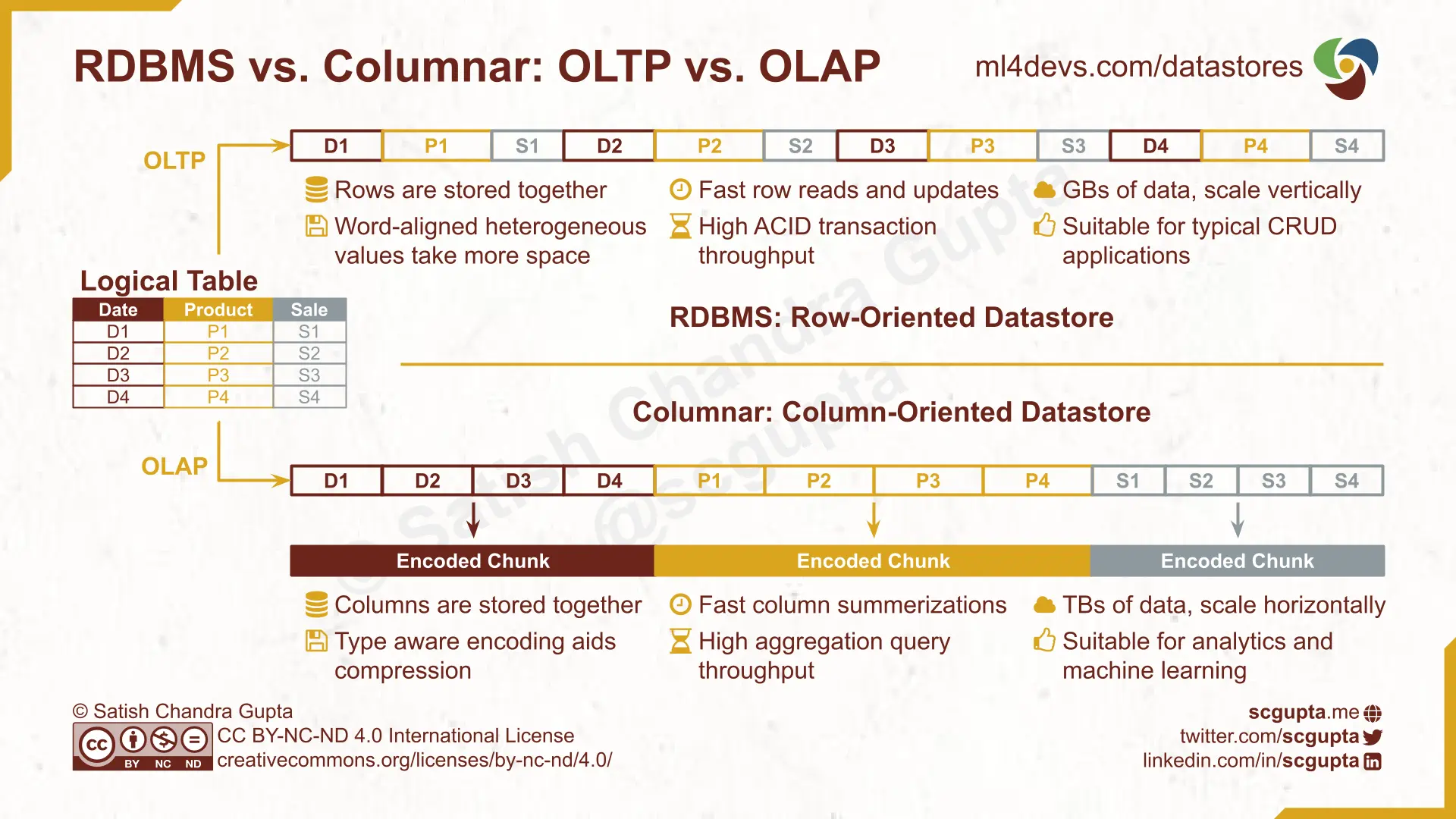
Relational Databases (RDBMS)
Relation Database Management Systems (RDBMS) are one of the earliest datastores. RDBMS are optimized for OLTP workloads requiring fast reading and updating a large number of rows. That’s why RDBMSs are row-oriented databases.
The data is organized in tables. Tables are normalized for reduced data redundancy and better data integrity.
Tables may have primary and foreign keys:
- Primary Key is a minimal set of attributes (columns) that uniquely identifies a record (row) in a table.
- Foreign Key establishes relationships between tables. It is a set of attributes in a table that refers to the primary key of another table.
Query and transactions are coded using Standard Query Language (SQL).
Relational databases are optimized for transaction operations. Transactions often update multiple records in multiple tables. Indexes are optimized for frequent low-latency writes of ACID Transactions:
- Atomicity: Any transaction that updates multiple rows is treated as a single unit. A successful transaction performs all updates. A failed transaction performs none of the updates, i.e., the database is left unchanged.
- Consistency: Every transaction brings the database from one valid state to another. It guarantees to maintain all database invariants and constraints.
- Isolation: Concurrent execution of multiple transactions leaves the database in the same state as if the transactions were executed sequentially.
- Durability: Committed transactions are permanent, and survive even a system crash.
There are plenty to choose from:
- Cloud Agnostic: Oracle, Microsoft SQL Server, IBM DB2, PostgreSQL, and MySQL
- AWS: Hosted PostgreSQL and MySQL in Relational Database Service (RDS)
- Microsoft Azure: Hosted SQL Server as Azure SQL Database
- Google Cloud: Hosted PostgreSQL and MySQL in Cloud SQL, and also horizontally scaling Cloud Spanner
Columnar Databases
While transactions are on rows (records), analytics properties are computed on columns (attributes). OLAP applications need an optimized column-read operation on a table. Columnar databases are designed for high-throughput of column aggregations. That’s why Columnar DBs are row-oriented databases.
One way to achieve it is by adding column-oriented indexes to Relational databases. For example:
However, the primary RDBMS operation is low-latency high-frequency ACID transactions. That does not scale to the Big Data scale common in analytics applications.
For Big Data, storing in blob storage Data Lakes became popular. Partial analytics summarizations were computed and maintained in OLAP Cubes. Advances in the scale and performance of Columnar storage made OLAP Cubes obsolete. But the concepts are still relevant for designing big data pipelines.
Modern Data Warehouses are built on Columnar databases. Data is stored by columns instead of by rows. Available choices are:
- AWS: RedShift
- Azure: Synapse
- Google Cloud: BigQuery
- Apache: Druid, Kudu, Pinot
- Others: ClickHouse, Snowflake
Databricks Delta Lake offers columnar-like performance on data stored in data lakes.
When to Use NoSQL Database
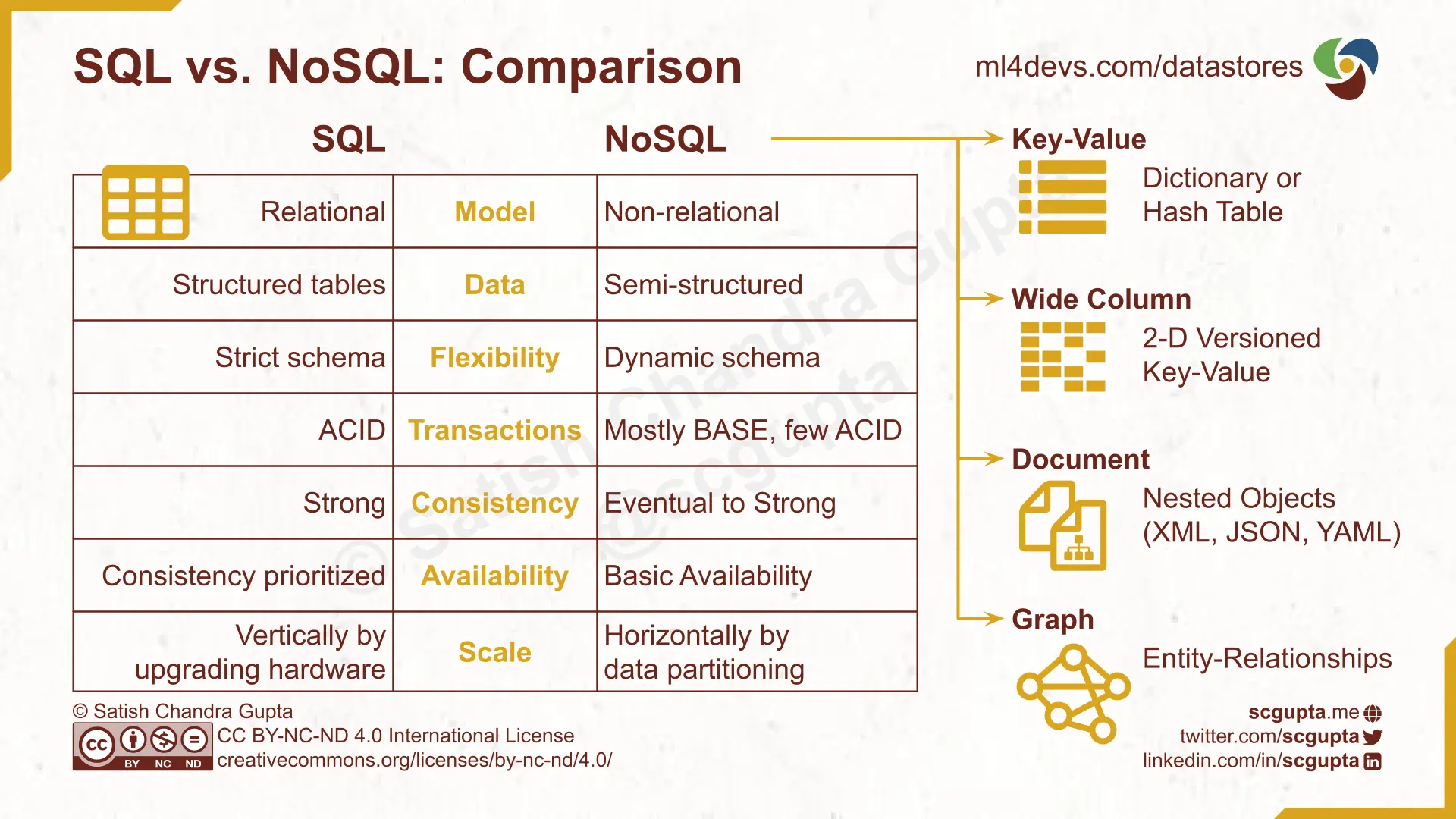
NoSQL databases cater to semi-structured data types: key-value, wide column, document (tree), and graph.
Key-Value Database
A key-value store is a dictionary or hash table database. It is designed for CRUD operations with a unique key for each record:
- Create(key, value): Add a key-value pair to the datastore
- Read(key): Lookup the value associated with the key
- Update(key, value): Change the existing value for the key
- Delete(key): Delete the (key, value) record from the datastore
The values do not have a fixed schema and can be anything from primitive values to compound structures. Key-value stores are highly partitionable (thus scale horizontally). Redis is a popular key-value store.
Wide-column Database
A wide-column store has tables, rows, and columns. But the names of the columns and their types may be different for each row in the same table. Logically, It is a versioned sparse matrix with multi-dimensional mapping (row-value, column-value, timestamp). It is like a two-dimensional key-value store, with each cell value versioned with a timestamp.
Wide-column datastores are highly partitionable. It has a notion of column families that are stored together. The logical coordinates of a cell are: (Row Key, Column Name, Version). The physical lookup is as following: Region Dictionary ⇒ Column Family Directory ⇒ Row Key ⇒ Column Family Name ⇒ Column Qualifier ⇒ Version. So, wide-column stores are actually row-oriented databases.
Apache HBase was the first open-source wide-column datastore. Check out HBase in Practice, for core concepts of wide-column datastores.
Document Database
Document stores are for storing and retrieving a document consisting of nested objects. a tree structure such as XML, JSON, and YAML.
In a key-value store, the value is opaque. But the document stores exploit the tree structure of the value to offer richer operations. MongoDB is a popular example of a document store.
Graph Database
Graph databases are like document stores but are designed for graphs instead of document trees. For example, a graph database will suit to store and query a social connection network.
Neo4J is a prominent graph database. It is also common to use JanusGraph kind of index over a wide-column store.
Difference between SQL and NoSQL
Non-relational NoSQL datastores gained popularity for two reasons:
- RDBMS did not scale horizontally for Big Data
- Not all data fits into strict RDBMS schema
NoSQL datastores offer horizontal scale at various CAP Theorem tradeoffs. As per CAP Theorem, a distributed datastore can give at most 2 of the following 3 guarantees:
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request gets a (non-error) response, regardless of the individual states of the nodes.
- Partition tolerance: The cluster does not fail despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
Note that the consistency definitions in CAP Theorem and ACID Transactions are different. ACID consistency is about data integrity (data is consistent w.r.t. relations and constraints after every transaction). CAP is about the state of all nodes being consistent with each other at any given time.
Only a few NoSQL datastores are ACID-complaint. Most NoSQL datastore support BASE model:
- Basically Available: Data is replicated on many storage systems and is available most of the time.
- Soft-state: Replicas are not consistent all the time; so the state may only be partially correct as it may not yet have converged.
- Eventually consistent: Data will become consistent at some point in the future, but no guarantee when.
SQL vs. NoSQL Database Comparison
Differences between RDBMS and NoSQL databases stem from their choices for:
- Data Model: RDBMS databases are used for normalized structured (tabular) data strictly adhering to a relational schema. NoSQL datastores are used for non-relational data, e.g. key-value, document tree, graph.
- Transaction Guarantees: All RDBMS databases support ACID transactions, but most NoSQL datastores offer BASE transactions.
- CAP Tradeoffs: RDBMS databases prioritize strong consistency over everything else. But NoSQL datastores typically prioritize availability and partition tolerance (horizontal scale) and offer only eventual consistency.
SQL vs. NoSQL Performance
RDBMS are designed for fast transactions updating multiple rows across tables with complex integrity constraints. SQL queries are expressive and declarative. You can focus on what a transaction should accomplish. RDBMS will figure out how to do it. It will optimize your query using relational algebra and find the best execution plan.
NoSQL datastores are designed for efficiently handling a lot more data than RDBMS. There are no relational constraints on the data, and it does not need to be even tabular. NoSQL offers performance at a higher scale by typically giving up strong consistency. Data access is mostly through REST APIs. NoSQL query languages (such as GraphQL) are not yet as mature as SQL in design and optimizations. So you need to take care of both what and how to do it efficiently.
RDBMS scale vertically. You need to upgrade hardware (more powerful CPU, higher storage capacity) to handle the increasing load.
NoSQL datastores scale horizontally. NoSQL is better at handling partitioned data, so you can scale by adding more machines.
NoSQL Use Cases
The line between various types of NoSQL datastore is blurry. On occasions, even the line between SQL and NoSQL is blurry (PostgreSQL as a key-value store and PostgreSQL as JSON document DB).
A datastore can be morphed to serve another similar data type by adding indexes and operations for that data type. Initial Columnar-like OLAP databases were RDBMS with column-store index. The same is happening to NoSQL stores for supporting multiple data types.
That’s why it is better to think about the use case and pick the datastore suitable for your application. A datastore that serves multiple use cases may help reduce the overhead.
For analytics use cases, a tabular columnar database is often more suitable than a NoSQL database.
Datastores with in-built operations suitable for the use case are preferred (instead of implementing those operations in each application).
In-memory Key-Value Data
Same as a key-value store, but the data is in the memory instead of on the disk. It eliminates the disk IO overhead and serves as a fast cache.
Time Series Data
A time series is a series of data points, indexed and ordered by timestamp. The timestamp is the key in the Time Series datastores.
A time series can be modeled as:
- Key-value: associated pairs of timestamps and values
- Wide column: with the timestamp as the key for the table
A wide column store with date-time functions from the programming languages is often used as a time series database.
In analytics use cases, a columnar database can be used for time-series data as well.
Immutable Ledger Data
Immutable Ledger is for maintaining an immutable and (cryptographically) verifiable transaction log owned by a central trusted authority.
From the storage perspective, a wide column store suffices. But datastore operations must be immutable and verifiable. Very few datastores (e.g. Amazon QLDB, Azure SQL Ledger, and Hyperledger Fabric) fulfill those requirements at present.
Geospatial Data
A Geospatial database is a database to store geographic data (such as countries, cities, etc.). It is optimized for geospatial queries and geometric operations.
A wide column, key-value, document, or relational database with geospatial queries is commonly used for this purpose:
In analytics use cases, a columnar database may suit better.
Text Search Data
Text search on unstructured (natural) or semi-structured text is a common operation in many applications. The text can either be plain or rich (e.g. PDF), stored in a document database, or stored in a blob store. Elastic Search has been a popular solution.
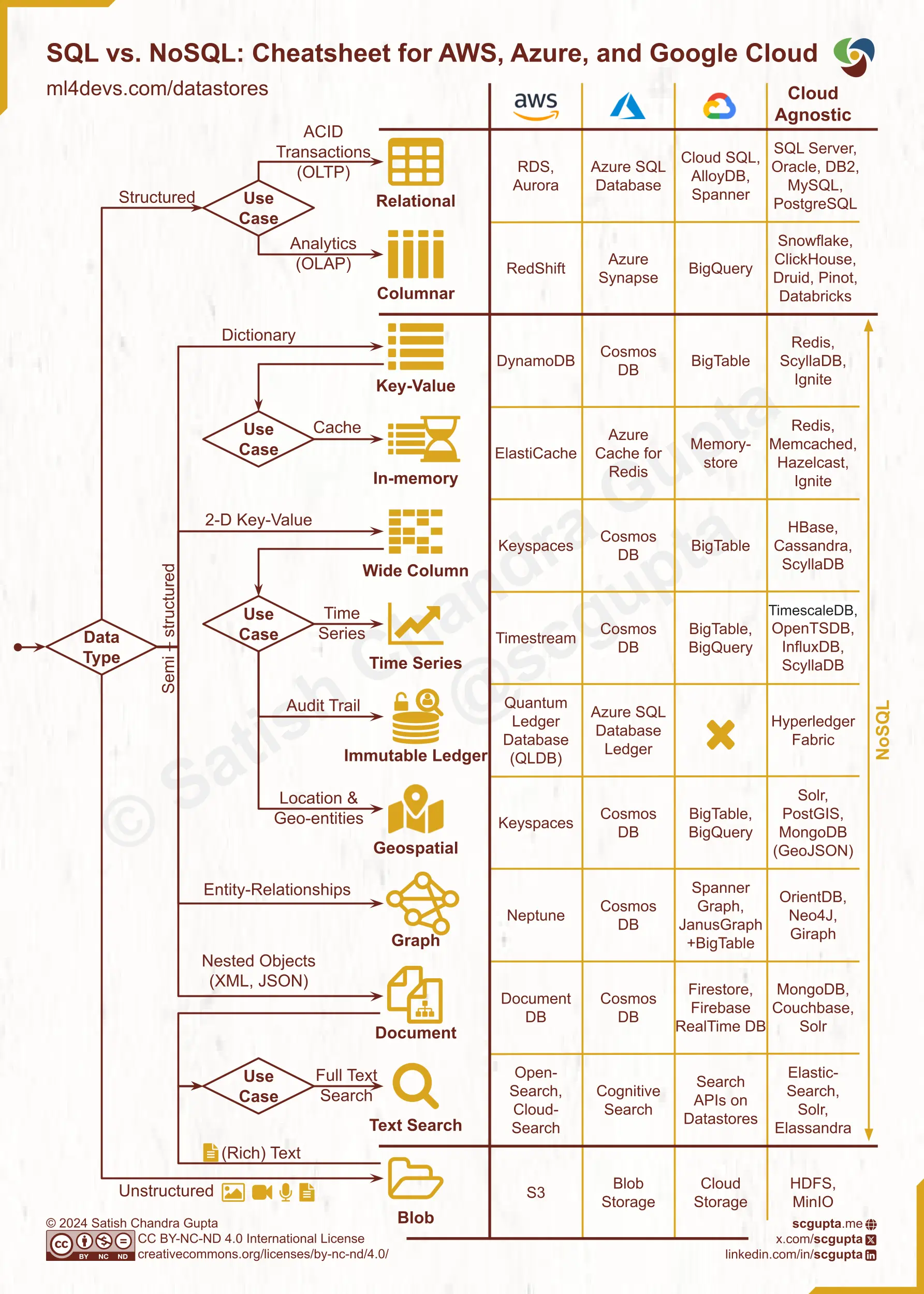
How to Choose NoSQL vs. SQL: Decision Tree & Cloud Cheat Sheet
Given so many data types, uses cases, choices, application considerations, and cloud/on-prem constraints, it can be time-consuming to analyze all options. The cheat sheet below will help you quickly shortlist a few candidates.
It is impractical to wait for learning everything needed to make a choice. This cheat sheet will get you a few reasonable choices to start with. It is simplified by design, and some nuances and choices are absent. It is optimized for recall instead of precision.
Summary
This article walked you through various datastore choices and explained how to pick one based on:
- Application: transactions or analytics
- Data Type (SQL vs. NoSQL): Structured, Semi-structured, unstructured
- Use Case
- Deployment: major cloud provider, on-prem, vendor lock-in considerations